读写分离
读写分离是通过主从的配置方式,将查询请求均匀的分散到多个数据副本,进一步的提升系统的处理能力。
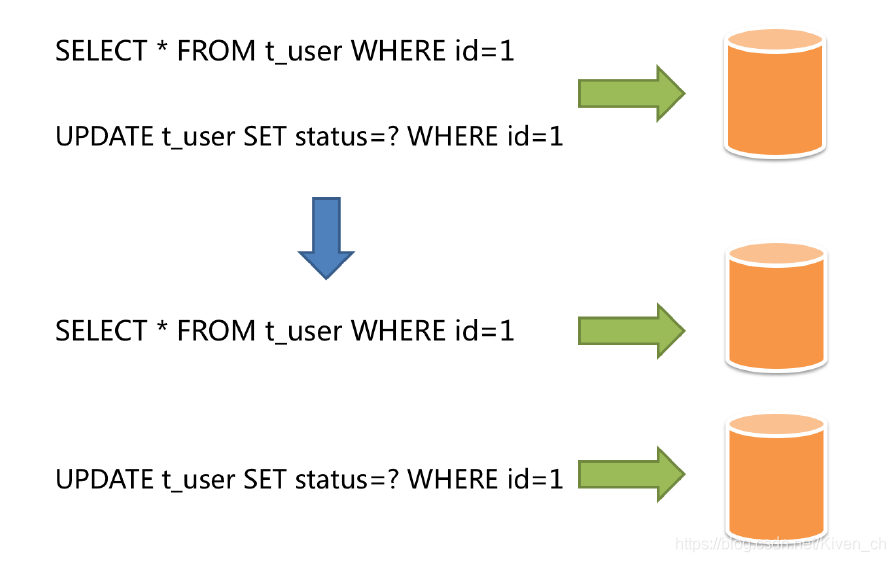
主从架构:读写分离,目的是高可用、读写扩展。主从库内容相同,根据SQL语义进行路由。
分库分表架构:数据分片,目的读写扩展、存储扩容。库和表内容不同,根据分片配置进行路由。
将水平分片和读写分离联合使用,能够更加有效的提升系统性能, 下图展现了将分库分表与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。
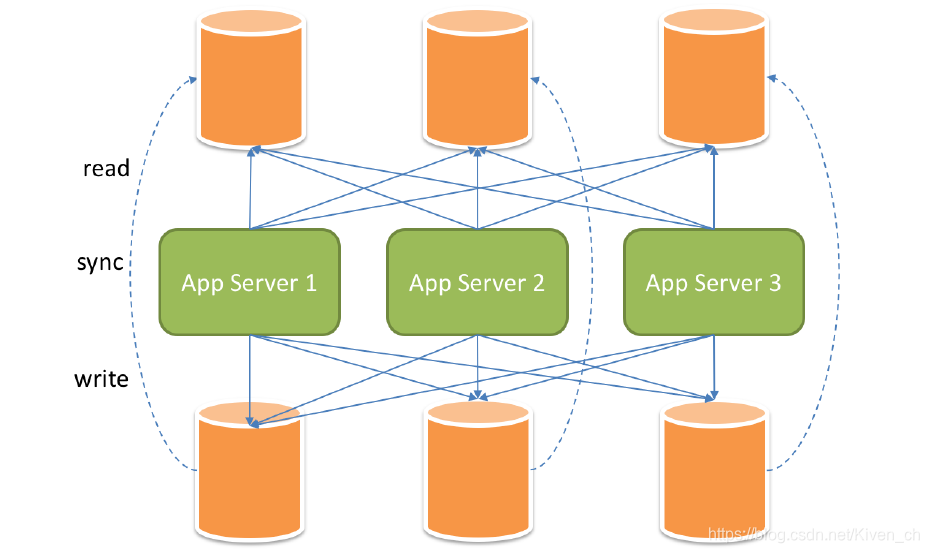
读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题,包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。
读写分离应用方案
在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下:
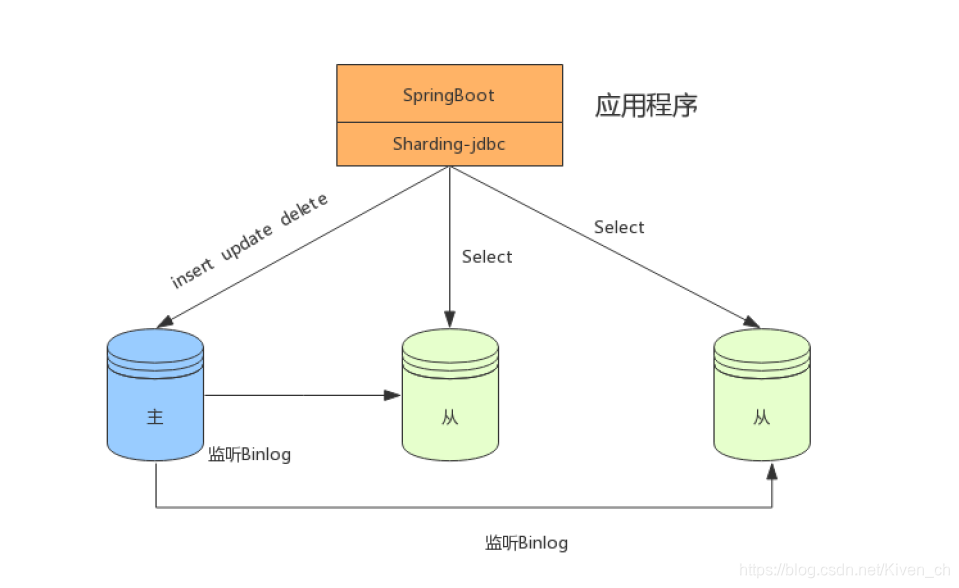
分表+读写分离
在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。
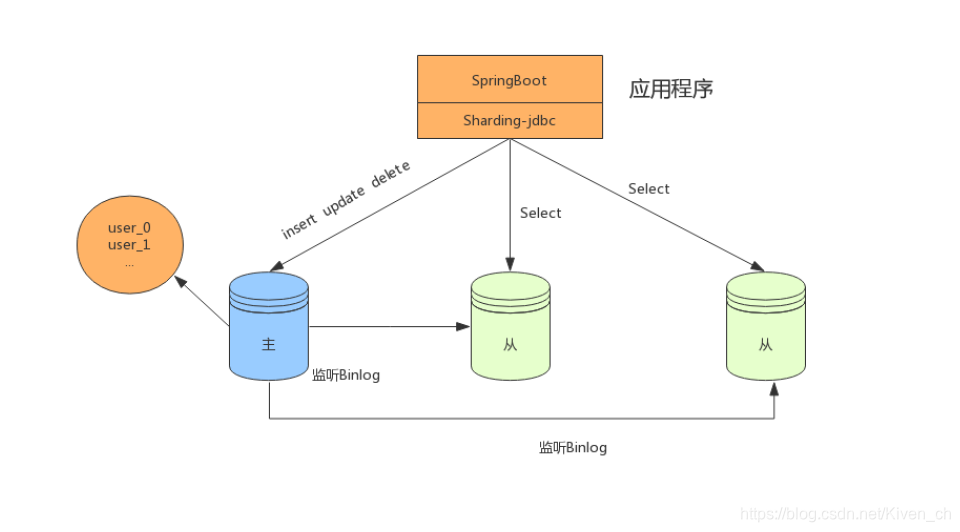
分库分表+读写分离
在数据量继续扩大,这时可以考虑分库分表,将数据存储在不同数据库的不同表中,如下:
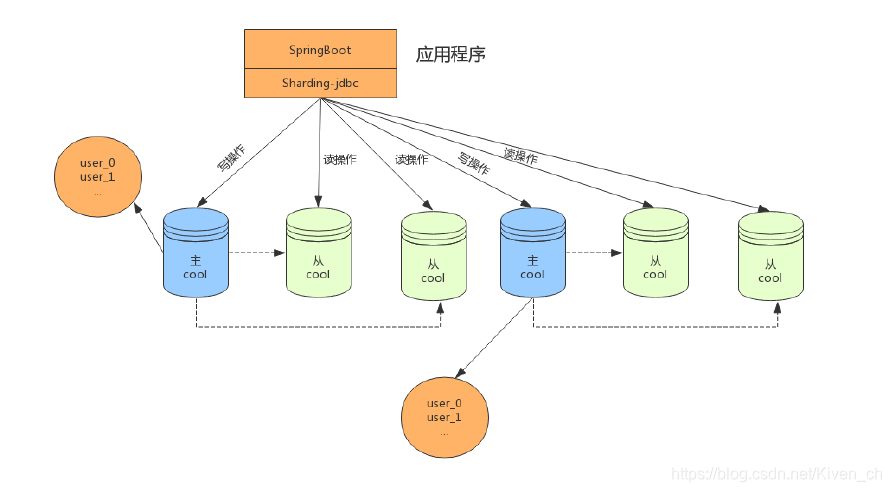
透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是ShardingSphere读写分离模块的主要设计目标。
主库、从库、主从同步、负载均衡
-
核心功能
-
提供一主多从的读写分离配置。仅支持单主库,可以支持独立使用,也可以配合分库分表使用
-
独立使用读写分离,支持SQL透传。不需要SQL改写流程
-
同一线程且同一数据库连接内,能保证数据一致性。如果有写入操作,后续的读操作均从主库读取。
-
基于Hint的强制主库路由。可以强制路由走主库查询实时数据,避免主从同步数据延迟。
-
-
不支持项
-
主库和从库的数据同步
-
主库和从库的数据同步延迟
-
主库双写或多写
-
跨主库和从库之间的事务的数据不一致。建议在主从架构中,事务中的读写均用主库操作。
-
读写分离配置
基于上一篇基本应用中使用的工程,对city表配置读写分离
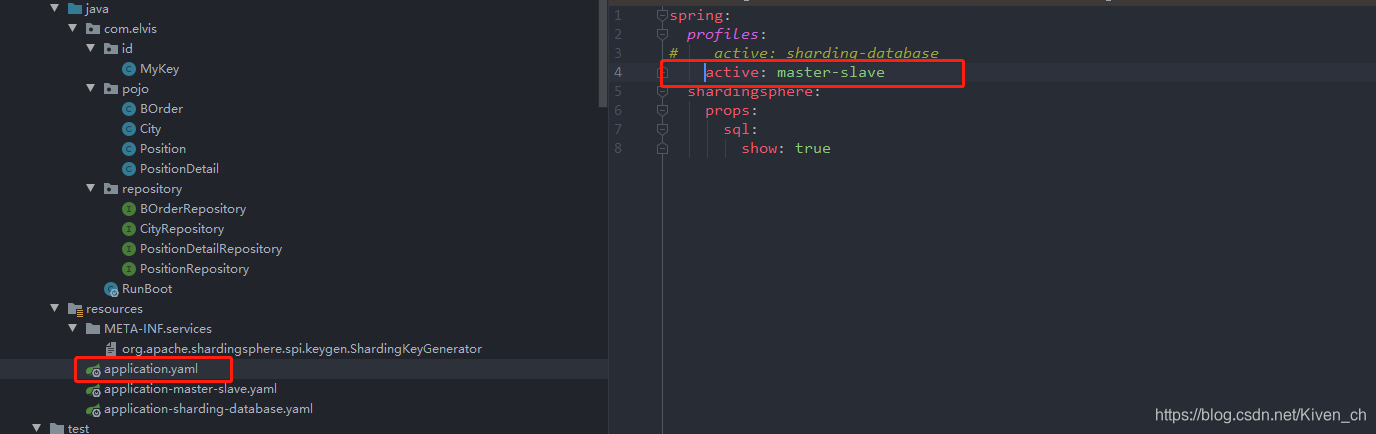
- 新建一个配置文件
application-master-slave.yaml,用于配置读写分离
#datasource
spring:
shardingsphere:
datasource:
names: master,slave0
master:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/sharding1?useSSL=false&characterEncoding=UTF-8
username: root
password: 123456
slave0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/sharding2?useSSL=false&characterEncoding=UTF-8
username: root
password: 123456
masterslave:
name:
master-data-source-name: master
slave-data-source-names: slave0
load-balance-algorithm-type: ROUND_ROBIN
sharding:
tables:
city:
key-generator:
column: id
type: SNOWFLAKE
- application中配置上面新建的配置文件生效
- 新建测试类
TestMasterSlave
@SpringBootTest
public class TestMasterSlave {
@Resource
private CityRepository cityRepository;
@Test
public void testAdd(){
City city = new City();
city.setName("shanghai");
city.setProvince("shanghai");
cityRepository.save(city);
}
@Test
public void testFind(){
List<City> list = cityRepository.findAll();
list.forEach(city->{
System.out.println(city.getId()+" "+city.getName()+" "+city.getProvince());
});
}
}
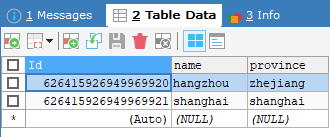
写操作路由到主库,读操作路由到从库

强制路由
官网地址如下:
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/usage/hint/
在一些应用场景中,分片条件并不存在于SQL,而存在于外部业务逻辑。因此需要提供一种通过在外部业务代码中指定路由配置的一种方式,在ShardingSphere中叫做Hint。如果使用Hint指定了强制分片路由,那么SQL将会无视原有的分片逻辑,直接路由至指定的数据节点操作。
HintManager主要使用ThreadLocal管理分片键信息,进行hint强制路由。在代码中向HintManager添加的配置信息只能在当前线程内有效。
Hint使用场景:
-
数据分片操作,如果分片键没有在SQL或数据表中,而是在业务逻辑代码中
-
读写分离操作,如果强制在主库进行某些数据操作
Hint使用过程:
- 编写分库或分表路由策略,实现HintShardingAlgorithm接口
public class MyHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(
Collection<String> availableTargetNames,
HintShardingValue<Long> shardingValue) {
Collection<String> result = new ArrayList<>();
for (String each : availableTargetNames){
for (Long value : shardingValue.getValues()){
if(each.endsWith(String.valueOf(value % 2))){
result.add(each);
}
}
}
return result;
}
}
-
在配置文件指定分库或分表策略
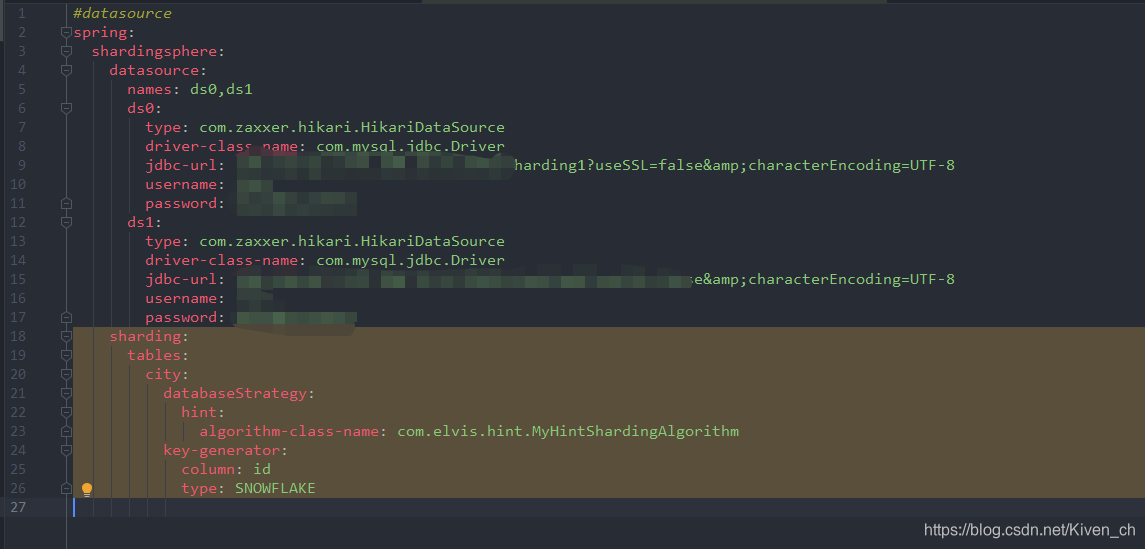
-
在代码执行查询前使用HintManager指定执行策略值
import com.elvis.pojo.City;
import com.elvis.repository.CityRepository;
import org.apache.shardingsphere.api.hint.HintManager;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.List;
@SpringBootTest
public class TestHintAlgorithm {
@Resource
private CityRepository cityRepository;
@Test
public void test1(){
HintManager hintManager = HintManager.getInstance();
hintManager.setDatabaseShardingValue(2L); //强制路由到ds${xx%2}
List<City> list = cityRepository.findAll();
list.forEach(city->{
System.out.println(city.getId()+" "+city.getName()+" "+city.getProvince());
});
}
}
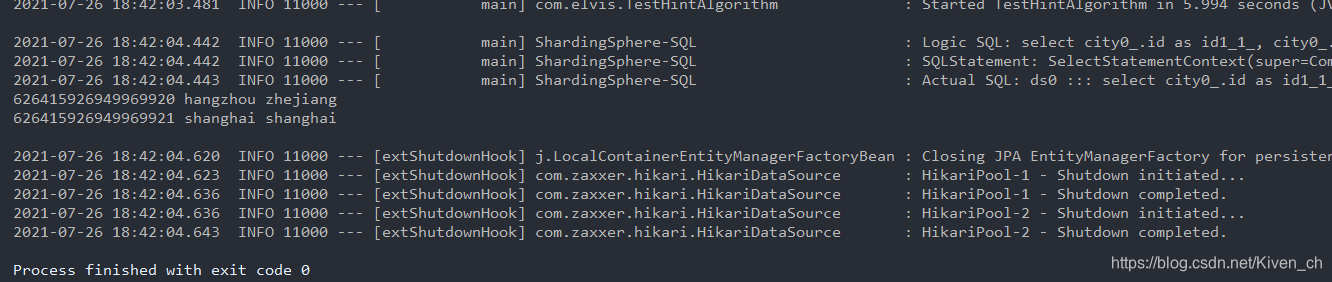
在读写分离结构中,为了避免主从同步数据延迟及时获取刚添加或更新的数据,可以采用强制路由走主库查询实时数据,使用hintManager.setMasterRouteOnly设置主库路由即可。
数据脱敏
数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。涉及客户安全数据或者一些商业性敏感数据,如身份证号、手机号、卡号、客户号等个人信息按照规定,都需要进行数据脱敏。
数据脱敏模块属于ShardingSphere分布式治理这一核心功能下的子功能模块。
-
在更新操作时,它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将密文数据存储到底层数据库。
-
在查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用
户。
Apache ShardingSphere自动化&透明化了数据脱敏过程,让用户无需关注数据脱敏的实现细节,像使用普通数据那样使用脱敏数据。
整体架构
官网地址
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/orchestration/encrypt/
ShardingSphere提供的Encrypt-JDBC和业务代码部署在一起。业务方需面向Encrypt-JDBC进行JDBC编程。
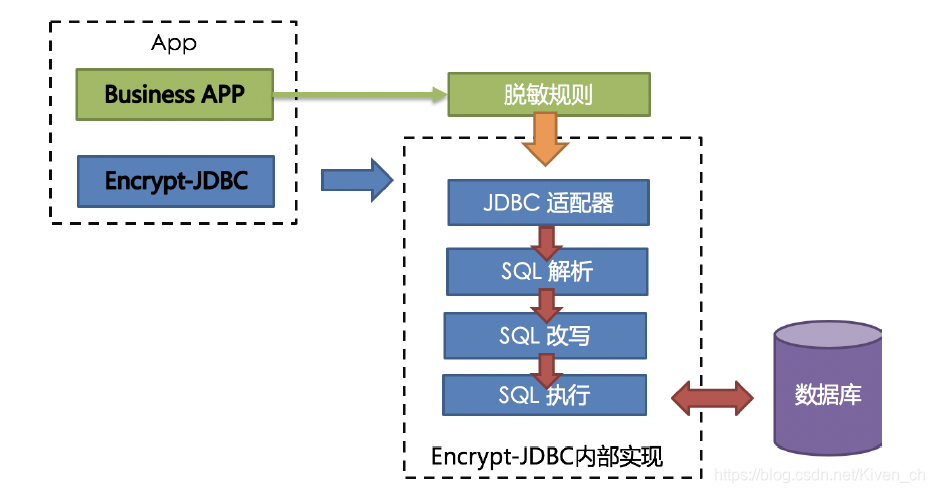
Encrypt-JDBC将用户发起的SQL进行拦截,并通过SQL语法解析器进行解析、理解SQL行为,再依据用户传入的脱敏规则,找出需要脱敏的字段和所使用的加解密器对目标字段进行加解密处理后,再与底层数据库进行交互。
脱敏规则
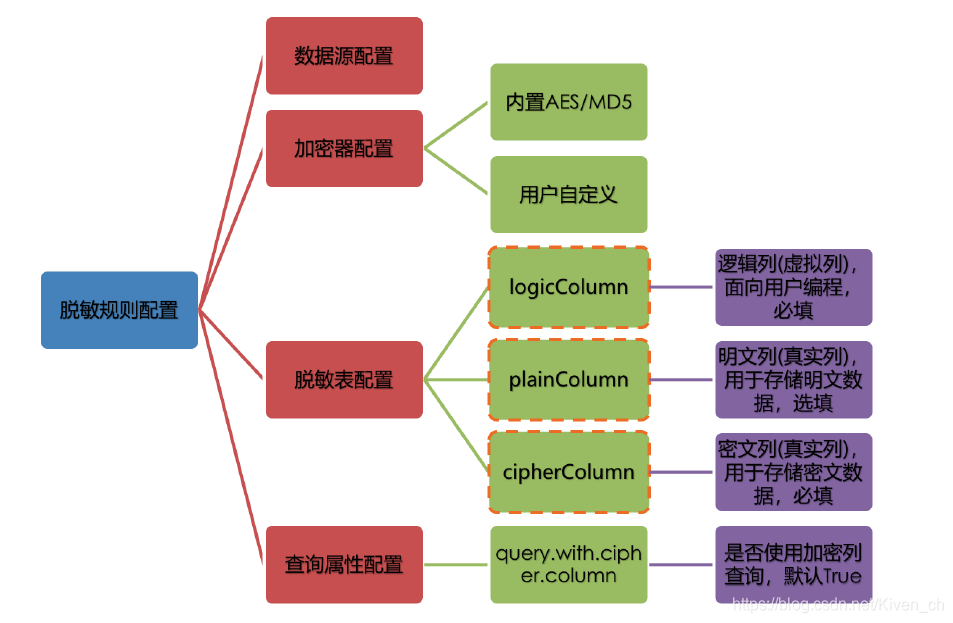
脱敏配置主要分为四部分:数据源配置,加密器配置,脱敏表配置以及查询属性配置,其详情如下图所示:
-
数据源配置:指DataSource的配置信息
-
加密器配置:指使用什么加密策略进行加解密。目前ShardingSphere内置了两种加解密策略:AES/MD5
-
脱敏表配置:指定哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行SQL编写(logicColumn)
-
查询属性的配置:当底层数据库表里同时存储了明文数据、密文数据后,该属性开关用于决定是直接查询数据库表里的明文数据进行返回,还是查询密文数据通过Encrypt-JDBC解密后返回。
脱敏处理流程
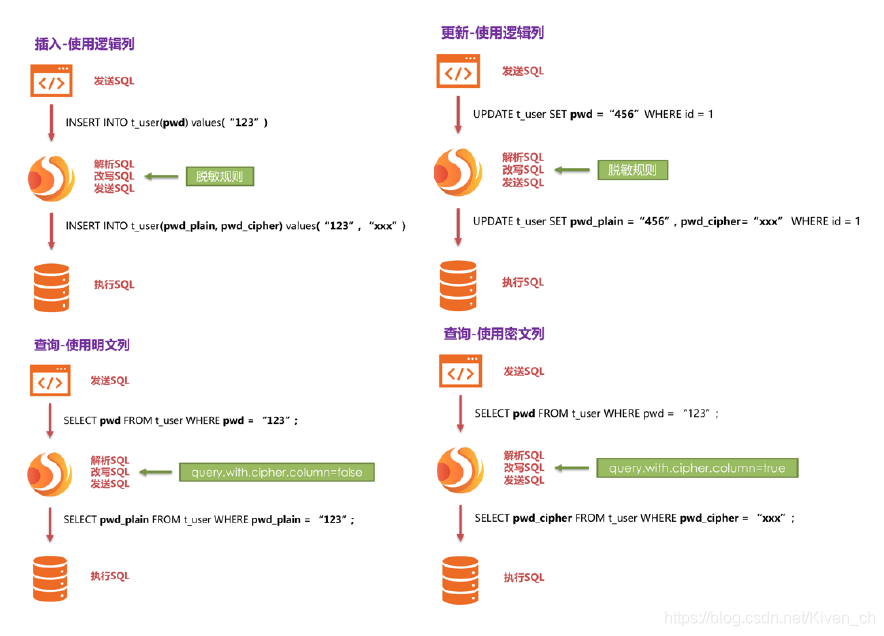
下图可以看出ShardingSphere将逻辑列与明文列和密文列进行了列名映射。
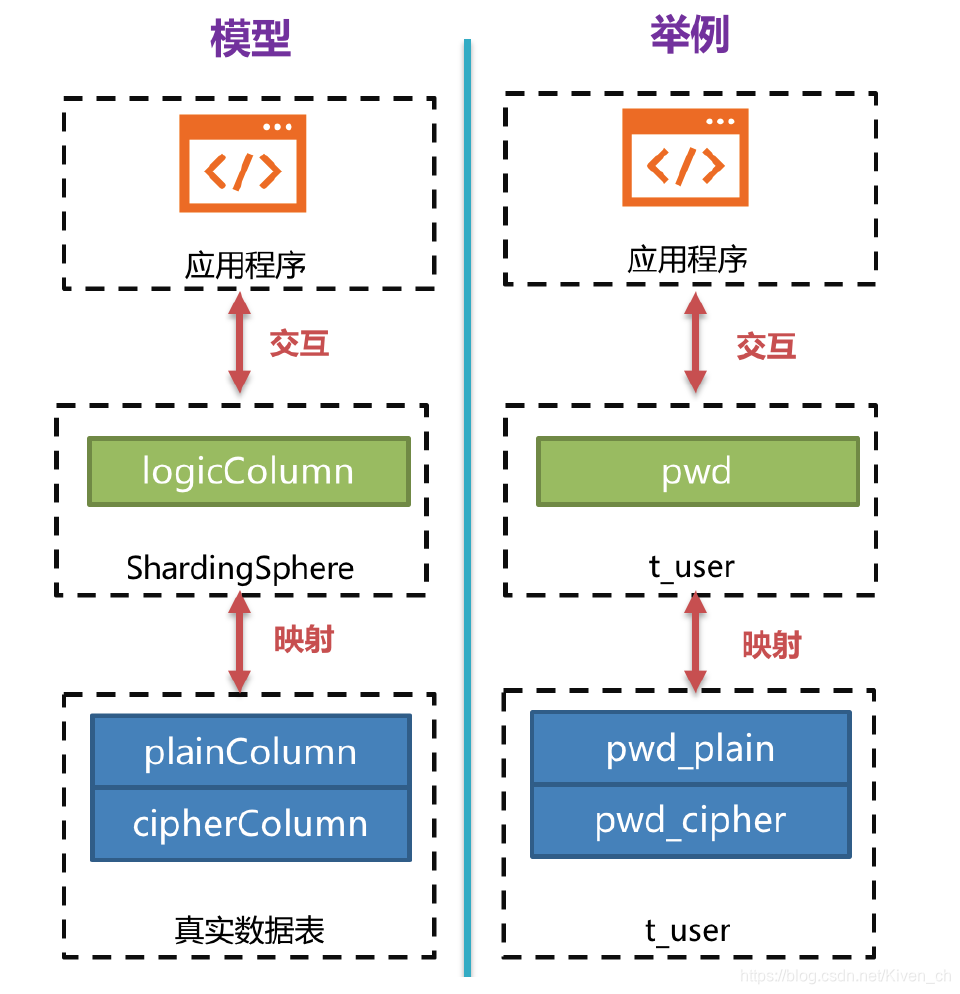
下方图片展示了使用Encrypt-JDBC进行增删改查时,其中的处理流程和转换逻辑,如下图所示。
加密策略解析
ShardingSphere提供了两种加密策略用于数据脱敏,该两种策略分别对应ShardingSphere的两种加解密的接口,即Encryptor和QueryAssistedEncryptor。
-
Encryptor
该解决方案通过提供encrypt(), decrypt()两种方法对需要脱敏的数据进行加解密。在用户进行INSERT, DELETE, UPDATE时,ShardingSphere会按照用户配置,对SQL进行解析、改写、路由,并会调用encrypt()将数据加密后存储到数据库, 而在SELECT时,则调用decrypt()方法将从数据库中取出的脱敏数据进行逆向解密,最终将原始数据返回给用户。当前,ShardingSphere针对这种类型的脱敏解决方案提供了两种具体实现类,分别是MD5(不可逆),AES(可逆),用户只需配置即可使用这两种内置的方案。
-
QueryAssistedEncryptor
相比较于第一种脱敏方案,该方案更为安全和复杂。它的理念是:即使是相同的数据,如两个用户的密码相同,它们在数据库里存储的脱敏数据也应当是不一样的。这种理念更有利于保护用户信息,防止撞库成功。它提供三种函数进行实现,分别是
encrypt(),decrypt(),queryAssistedEncrypt()。在encrypt()阶段,用户通过设置某个变动种子,例如时间戳。针对原始数据+变动种子组合的内容进行加密,就能保证即使原始数据相同,也因为有变动种子的存在,致使加密后的脱敏数据是不一样的。在decrypt()可依据之前规定的加密算法,利用种子数据进行解密。queryAssistedEncrypt()用于生成辅助查询列,用于原始数据的查询过程。由于
queryAssistedEncrypt()和encrypt()产生不同加密数据进行存储,而decrypt()可逆,queryAssistedEncrypt()不可逆。 在查询原始数据的时候,我们会自动对SQL进行解析、改写、路由,利用辅助查询列进行 WHERE条件的查询,却利用decrypt()对encrypt()加密后的数据进行解密,并将原始数据返回给用户。这一切都是对用户透明化的。当前,ShardingSphere针对这种类型的脱敏解决方案并没有提供具体实现类,却将该理念抽象成接口,提供给用户自行实现。ShardingSphere将调用用户提供的该方案的具体实现类进行数据脱敏。
配置数据脱敏
- 在sharding库中创建user表
USE sharding1;
CREATE TABLE `c_user` (
`Id` BIGINT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(256) DEFAULT NULL,
`pwd_plain` VARCHAR(256) DEFAULT NULL,
`pwd_cipher` VARCHAR(256) DEFAULT NULL,
PRIMARY KEY (`Id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
- 创建实体类
@Entity
@Table(name = "c_user")
public class CUser {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
// 逻辑列名
@Column(name = "pwd")
private String pwd;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
}
- 创建jpa repository类
public interface CUserRepository extends JpaRepository<CUser,Long> {
public List<CUser> findByPwd(String pwd);
}
- 创建
application-encrypt-database.yaml文件
#datasource
spring:
shardingsphere:
datasource:
names: ds0
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/sharding1?useSSL=false&characterEncoding=UTF-8
username: root
password: 123456
encrypt:
tables:
c_user:
columns:
pwd:
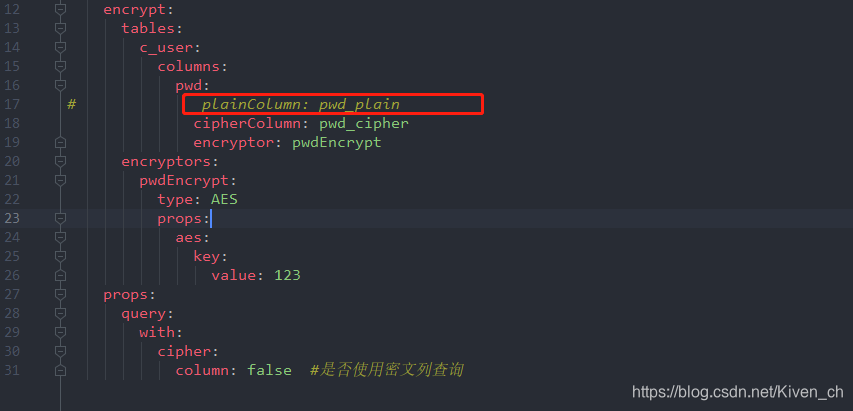
plainColumn: pwd_plain
cipherColumn: pwd_cipher
encryptor: pwdEncrypt
encryptors:
pwdEncrypt:
type: AES
props:
aes:
key:
value: 123
props:
query:
with:
cipher:
column: false #是否使用密文列查询
- 创建测试类
import com.elvis.pojo.CUser;
import com.elvis.repository.CUserRepository;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.Repeat;
import javax.annotation.Resource;
import java.util.List;
@SpringBootTest
public class TestEncryptor {
@Resource
private CUserRepository userRepository;
@Test
@Repeat(2)
public void testAdd(){
CUser user = new CUser();
user.setName("tiger");
user.setPwd("abc");
userRepository.save(user);
}
@Test
public void testFind(){
List<CUser> list = userRepository.findByPwd("abc");
list.forEach(cUser -> {
System.out.println(cUser.getId()+" "+cUser.getName()+" "+cUser.getPwd());
});
}
}
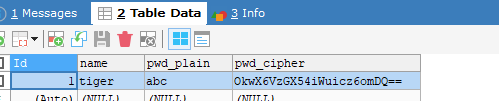

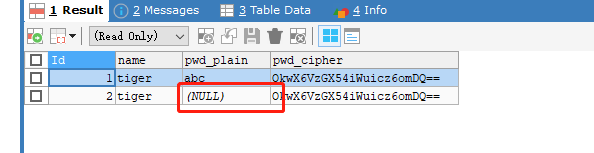
- 如果在配置文件注释掉逻辑列到实体列明文的映射配置,则只会存入秘文列
原文链接: https://blog.csdn.net/Kiven_ch/article/details/119114941